一、业务场景
由于数据加工完成的数据,需要给不同的应用和产品提供服务,包含:数据产品、实时大屏、线上应用、BI自主分析。
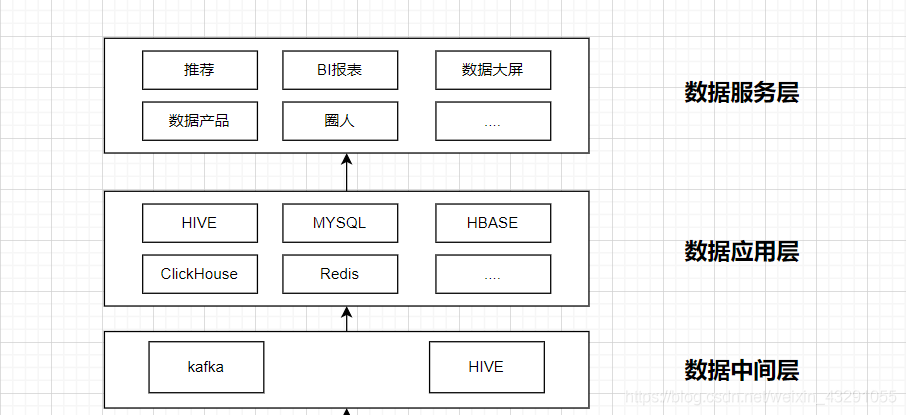
由于业务场景不同,在不同的场景下选择的数据存储也不同,例如:Hive、Mysql、Hbase、CK、redis、TiDB等等。最后产生的调用服务也多样。如下一些场景:
- 线上推荐服务:高QPS、低RT
- 智能营销圈人:需要圈选大量人群数据,人群数量百万、甚至千万
- 实时大屏:需要支持数据实时推送更新
- 数据产品、BI分析:报表2w+、产品数据数据服务10w+
因此数据服务统一化非常必要。根据上述业务场景,需要解决下列问题:
(1)数据服务统一化:接口不同QPS和RT,不同的接口服务(HTTP、RPC、文件传输等),即:OneAPI
(2)存储解析统一化:一套语言支持多种数据存储接入,即:OneSQL
(3)数据模型统一化:支持多种数据源接入, 即:OneModel
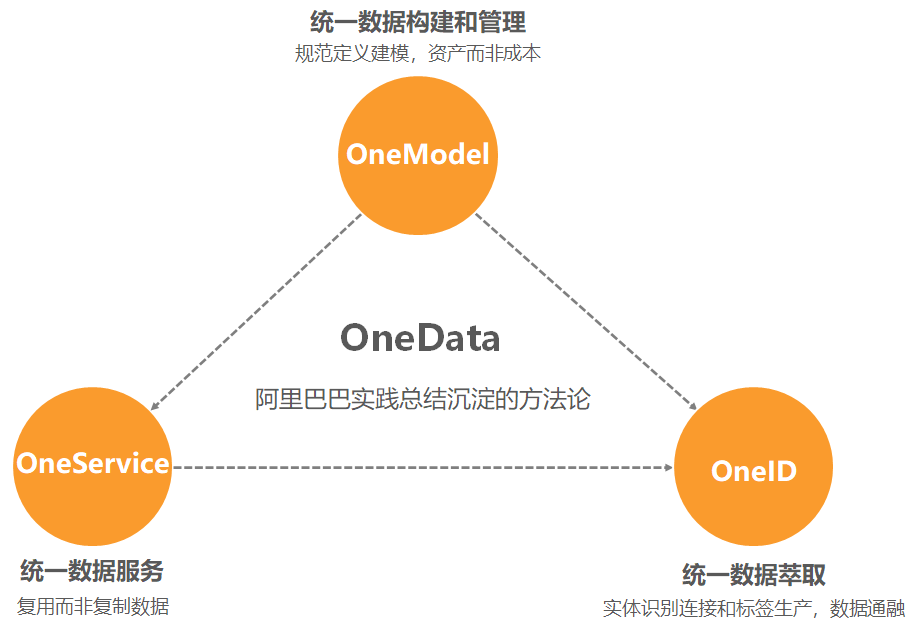
相信大家都听说过阿里巴巴的OneData方法论。在这一方法论下大数据工程师,构建统一、规范、可共享的全域数据提醒,避免数据的冗余和重复建设,规避数据烟囱和不一致性,充分发挥阿里巴巴在大数据海量、多样性方面的独特优势。
二、建设思路
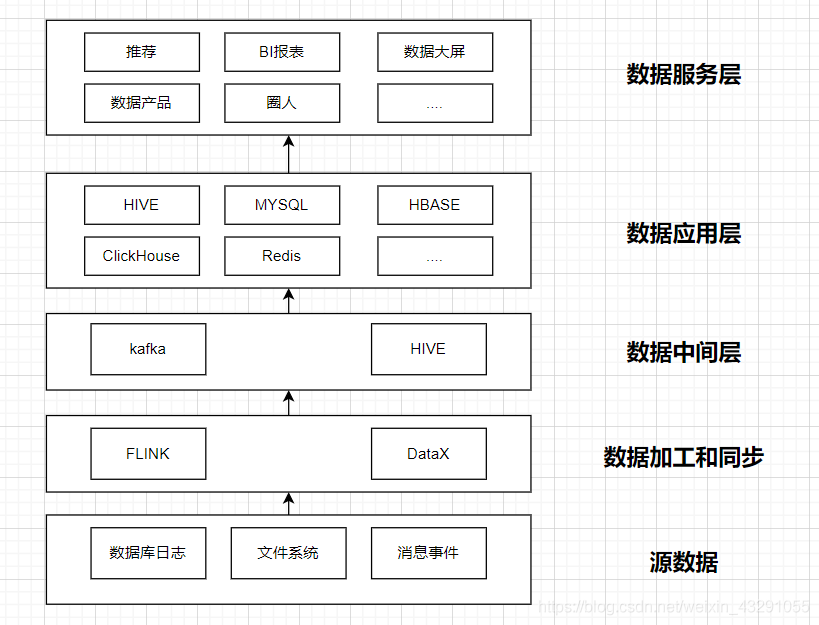
在大数据建设过程中,思路是这样的:数据埋点——数据采集——数据清洗(ETL)——数据服务——数据可视化。
整体流程如下图:
三、架构设计
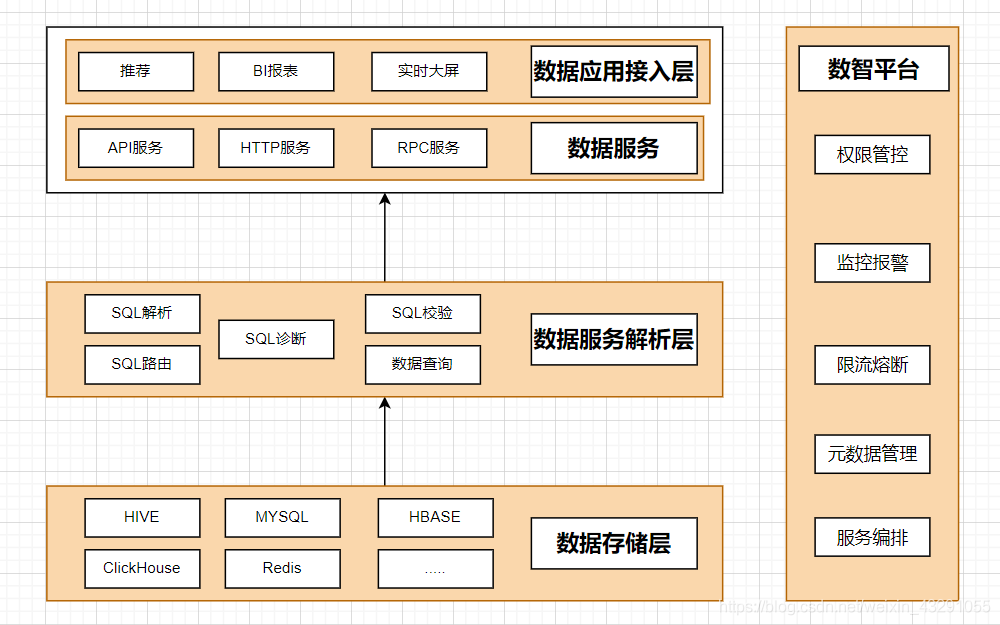
数据服务平台能够解决数据服务统一化,便于数据服务的治理、指标口径的统一。能够提升业务的开发效率,更快的面对业务的变化。数据服务平台主要分如下三层:
1、数据应用接入层
主要是针对外部应用接入,包含:HTTP服务、RPC服务、Client 服务。
2、数据服务解析层
主要通过SQL方式访问各种数据存储,然后生成对应数据服务。核心功能:SQL解析、SQL校验、SQL路由、数据查询。
3、数据存储层
主要包含数据的存储管理,MySQL、Redis、Hive等等。都能很好的支持,提供API服务。
四、数据服务生产的流程
1、选择数据存储
2、配置数据查询SQL
//统计某一天的每个店铺的销售额
select
shop_id,sum(gmv) as total_gmv from (
select * from table where dt=#{dt}
) t
group by shop_id;
3、根据选择数据存储引擎,将SQL转化成可执行的语言进行执行。
基于Apache Calcite 进行开发主要步骤如下:
Parser -> Validate -> Route -> Optimize -> Execute -> Limit
(1)Parser:此步中Calcite通过Java CC将SQL解析成未经校验的AST
(2)Validate: 该步骤主要作用是校证Parser步骤中的AST是否合法,如验证SQL scheme、字段、函数等是否存在; SQL语句是否合法等. 此步完成之后就生成了RelNode树
(3)Optimize: 该步骤主要的作用优化RelNode树, 并将其转化成物理执行计划。主要涉及SQL规则优化如:基于规则优化(RBO)及基于代价(CBO)优化; Optimze 这一步原则上来说是可选的, 通过Validate后的RelNode树已经可以直接转化物理执行计划,但现代的SQL解析器基本上都包括有这一步,目的是优化SQL执行计划。此步得到的结果为物理执行计划。
(4)Execute:即执行阶段。此阶段主要做的是:将物理执行计划转化成可在特定的平台执行的程序。根据选择的数据存储引擎,将SQL对应转化程可执行的程序。
(5)Limit:即SQL限流。此阶段主要是针对SQL耗时进行监控、发现SQL耗时极大会进行限流管控。关于SQL限流的解释,可参考:阿里数据库性能诊断的利器——SQL执行干预_weixin_33856370的博客-CSDN博客
至此一个API服务就完完整整的生成了,可以理解为一个原子服务。
但是问题仍然来了,生产了一个根据用户id查询订单的原子服务A,生产一个根据订单id查询商品的信息的原子服务B。流程图如下:

如果需要查询出某个用户下某个订单的所有商品信息,就需要先调用订单服务API,然后根据返回的结果调用商品服务API,最后才能拿到想要的信息。
显然:当调用的服务越多,需要手动开发的成本越来越高,以及中间的数据转化部分也需要进行开发,效率极低。
针对原子服务的互相调用以及参数转化如果进行手动开发,那么有没有一种简单操作就能实现参数转化和服务串接呢?
服务编排应运而生。
4、服务编排
指对于原子服务进行串接、参数转换,以及一些业务逻辑的判断进行处理。下面只是简单称述如下三种情况:
(1)服务串行:

(2)服务并行:
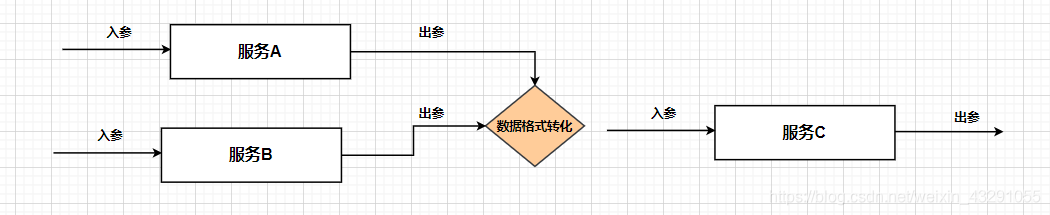
(3)服务逻辑校验:
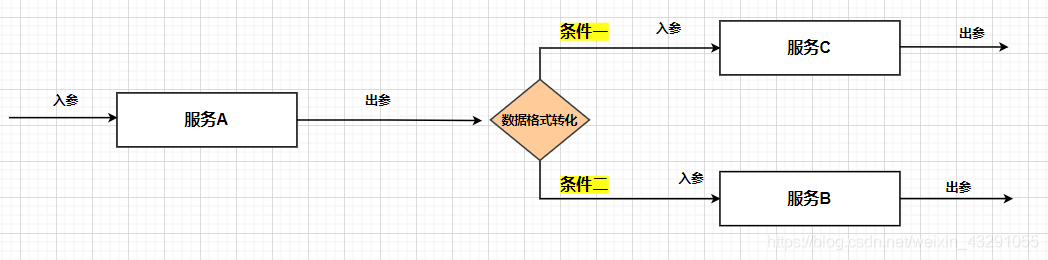
四、总结
本篇文章介绍大数据服务平台整体建设思路,也存在很多的疏漏仍需不断的实践和修改。