一、原理
爬虫就是把互联网上的数据,抓取下来,存到自己的本地的程序。
以百度为例,爬取一个个的网页,存到自己库中,当我们搜索的时候,去百度的数据库中搜索,显示在前端,点击某个页面,直接跳转到真正的地址。
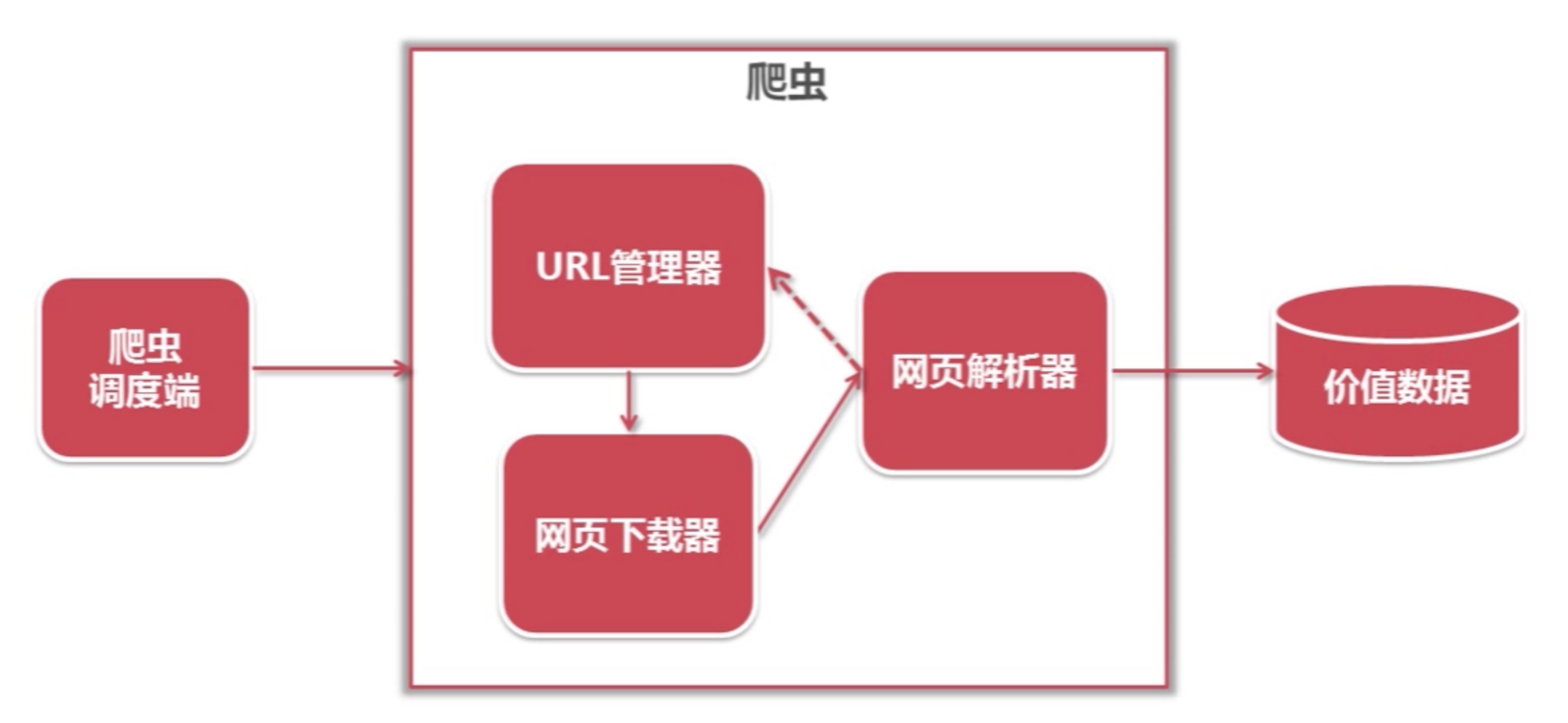
1、基本原理
发送http请求(requests)-> 返回数据 -> 解析数据(数据清洗,bs4,re…) -> 入库(文件,excel,mysql,redis,mongodb)
注意:爬取数据时,如果被禁止了,一定是你伪装得还不够像。
2、爬虫协议
每个网站都有robots.txt文件,它是一个协议,规定了哪些允许你爬,哪些不允许你爬(君子协议)
3、反爬虫的方法
(1)验证码
(2)封ip
(3)封账号
(4)js逆向:js比较不错
(5)app爬取:加密
(6)app逆向:java,动态调试so文件(汇编)
4、Python爬虫所需要的工具
请求库:requests,selenium
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongodb,Redis
5、爬虫常用框架
scrapy
二、请求库requests使用方法
请求库是模拟发送http请求(只要http请求有的东西,都可以使用requests发送出去)。
python内置的urllib2、urllib3,不太好用,用起来比较麻烦。
requests是某大神基于urllib3封装的库,后来又封装了一个requets-html库,python界非常出名的第三方库。
1、安装
pip3 install requests
2、基本使用方法
import requests
# res对象中会有,响应体,响应头,cookie。。。。
# 请求头中带User-Agent,是客户端类型
# 加入请求头
res = requests.get('https://dig.chouti.com/',headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
})
print(res.text) # 响应体,转成了字符串
with open('a.html','w',encoding='utf-8') as f:
f.write(res.text)
# 另外一种使用
requests.request('post',cookies={})
3、带参数的GET请求
# 方式一:get请求参数,直接拼接在路径中
response = requests.get('https://www.baidu.com/s?wd=老张的博客',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
})
with open('baidu.html', 'w', encoding='utf-8') as f:
f.write(response.text)
# 方式二:使用params参数
response = requests.get('https://www.baidu.com/s',
params={'wd': '老张的博客'},
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
})
with open('baidu.html', 'w', encoding='utf-8') as f:
f.write(response.text)
4、带参数的GET请求(headers版)
import requests
# res对象中会有,响应体,响应头,cookie。。。。
# 请求头中带User-Agent,是客户端类型
# referer:上一次请求的地址,做图片防盗链
# cookie:cookie信息
# 加入请求头
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
'referer':'https://www.webppp.com/'
}
res = requests.get('https://www.webppp.com/view/python_spider.html',headers=header)
print(res.text) # 响应体,转成了字符串
referer:比如向这个图片地址发请求,会有referer,检测referer是不是这个网站的,不是则禁止。
5、带参数的GET请求(cookies版)
# 方式一:带在请求头中
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
'cookie':'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiIwZmVlMjk5OS1iMDgzLTRmYzctOTM4MC03YjIzZmVmY2U5YmYiLCJleHBpcmUiOiIxNjIzOTA0ODk5MzM5In0.7cadtBYznS6OgnLwEF8aH0AmtDOoYB1WKDgdU4eYYS0; __snaker__id=VbChmBUEZIVY3FPa; _9755xjdesxxd_=32; YD00000980905869%3AWM_TID=%2FazmF9%2FrClJFEVFBVRN70z7msH6De39Y; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1631674964,1634180671,1634183906; gdxidpyhxdE=SmmnuyrMOQB%2B9hzOlIaMPx0O9ZJbqWBllx7aa1OTmRwgGymo94mTYgZ0DrUWw7tfx8qIZmRt01BbIVX2jIc30jqSzPWznXpll6kBokS56266%2FmPg%2BC%5CvNV%2BJhO%5C9ln%2FQdskmo%2FH5A%2BLOADRDACtDp59%5CH51jexwMSIXSA9atTxuJDXOn%3A1634184810108; YD00000980905869%3AWM_NI=WlPwT2GigeoAGFNAH66LZluq3E87sk7E%2Bn6YtGANtE0G%2Bke2f0x6a1rG8kACozd%2FrWBXr3ne%2FBnps6fdDDeTm052UXP1VES3VxQISaL9zd91nvo%2FON%2FVuXS9INJSQYS%2FOG8%3D; YD00000980905869%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee97c96aadeda38de27286ef8bb3d45a828f8babae8095aea8d0b47e9191e186c42af0fea7c3b92a95b4a098d73a85b7a986ee4b859a82a2cb3ef694968df87bf19bf8d8f261f59be58fb553b8998faff74ff499e58ce83aa6f0b8d7e43bb299f88cc449ada6acd0f15d8288bed4ed6fed9ea291f23ea6bc8ca5e860aff0fbd3d85494ef9aa6d23996a89faad26b90e7b685bc3baeaaa1d0ce46ed8abbb9d2338b9286b4d45391f181a8bb37e2a3; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNjM2Nzc1OTIyMTI2In0.o5-Y9-USxFog5sdo1WR1WORUzPkUD4fozEVA_f0WSHU; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1634183939'
}
# post请求,携带在请求体中的数据
res=requests.post('https://www.webppp.com/view/python_spider.html',data={'linkId': '32667354'},headers=header)
#https://www.webppp.com/view/python_spider.html
print(res.text)
# 方式二:直接以参数形式传入,cookie会经常用,而且一般是字典形式,提供了一个cookie参数
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
# cookies需要是:Dict or CookieJar object
res = requests.post('https://dig.chouti.com/link/vote', data={'linkId': '32667354'}, headers=header,cookies={})
print(res.text)
6、POST请求
# 发送post请求,模拟浏览器的登录行为
header = {
'Referer': 'https://www.webppp.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
res = requests.post('https://www.webppp.com/', headers=header, data={
'username': 'webppp',
'password': 'xxx',
'captcha': 'fmd8',
'remember': 1,
'ref': 'https://www.webppp.com/',
'act': 'act_login',
})
# 获取到cookie,登陆过后的cookie
cookie = res.cookies
print(cookie) # CookieJar
res1 = requests.get('https://www.webppp.com/', headers=header, cookies=cookie)
# res1=requests.get('https://www.webppp.com/',headers=header)
print('webppp' in res1.text)
7、响应Response
import requests
respone=requests.get('https://www.webppp.com/')
# respone属性
print(respone.text) # body的内容转成str类型
print(respone.content) # body的二进制内容 (图片,视频)
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 把响应的cookie转成了cookiejar的对象
print(respone.cookies.get_dict()) # 把cookiejar的对象转成字典
print(respone.cookies.items()) # key和value
print(respone.url) # 请求的地址
print(respone.history) # 请求历史,重定向,才有数据,列表
print(respone.encoding) # 响应的编码格式
response.iter_content() #循环它,如果是视频,一点一点保存
解析json(http请求返回的数据是json格式):
res.text是json字符串,取值不好取,需要json.loads(res.text)转成字典,再取值。
直接res.json()转成json后的字典形式
import requests
res = requests.post('https://www.webppp.com/', data={
'cname': '',
'pid': '',
'keyword': '上海',
'pageIndex': 1,
'pageSize': 10,
})
# print(res.text)
print(type(res.json()))
8、编码问题
url编码问题 把中文用url编码,把url编码解成中文
# https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3
from urllib import parse
# 把中文用url编码,
res=parse.quote('美女')
print(res)
# 把url编码解成中文
res=parse.unquote('%E7%BE%8E%E5%A5%B3')
print(res)
网站编码,不是utf-8,使用res.text默认用utf-8转,可能出乱码
import requests
res=requests.get('')
# res.encoding='GBK'
res.encoding=res.apparent_encoding
print(res.text)
9、获取二进制数据
视频、图片需要保存二进制
import requests
res=requests.get('https://www.webppp.com/upload/python_spider.jpg')
with open('python_spider.jpg','wb') as f:
# f.write(res.content)
for line in res.iter_content(1024):
f.write(line)
10、request.session的使用
import requests
session = requests.session() # 可以帮咱们保持cookie,以后不用手动携带
header = {
'Referer': 'https://www.webppp.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
res = session.post('https://www.webppp.com/', headers=header, data={
'username': 'webppp',
'password': 'xxx',
'captcha': 'fmd8',
'remember': 1,
'ref': 'https://www.webppp.com/',
'act': 'act_login',
})
# 获取到cookie,登陆过后的cookie
# cookie=res.cookies
# print(cookie) # CookieJar
res1 = session.get('https://www.webppp.com/', headers=header)
print('webppp' in res1.text)
三、补充
什么是正向代理,什么是反向代理?
1、正向代理
隐藏客户端,翻墙软件。可以理解为买票的黄牛。
2、反向代理
隐藏服务器,nginx 是一个反向代理服务器。可以理解为租房的代理。